
Big Data : All Aboard the Information Bus
What is good for the short term is often not good for the long term.
A simple example from baseball:
As it became obvious that steroids enhanced performance, many players turned to the 'juice', to drive their short term performance. However, they quickly learned that it was not sustainable. Once you stop or overuse it, your performance and stability begins to breakdown. At the risk of picking on A-Rod, its fairly obvious when you look at a simple graph below. Note: the yellow star is when he admitted to starting to use steroids..
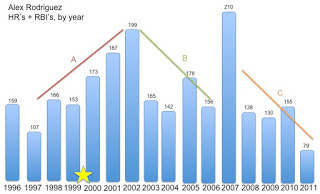
So, good for short term...disaster in the long term.
Turning to Big Data...
I believe an enterprise has to approach this problem with the long term in mind. There are a number of approaches for short term gratification, but they will not scale to support an enterprise economically in the long term. This is why I have alluded to the application server analogy for Big Data a few times (most recently here and here). Let me use some basic graphics to illustrate this analogy.
Typical/Simplistic View of an Enterpise

Simply put, an enterprise IT organization invests across all 3 layers and on integration inbetween.
However, as I look at emerging Big Data solutions, I'm seeing a pattern that looks like this:
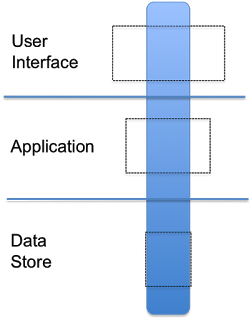
The blue bar represents a 3rd party product that provides the entire stack, in proprietary packaging. This approach drives instant gratification. There is a single purchase, the enterprise gets the entire stack, etc. There are new companies that have been successful with this model. But that being said, I am not convinced this is a great approach for an enterprise longer term. Here is why.
Unfortunately, enterprises are not as simple as I depicted above. They often look more like this:

Enterprises are complex, they evolve, they buy, they build, they customize, etc. If you try to take the 'proprietary stack' approach to solving your problems, your enterprise will eventually look like this:
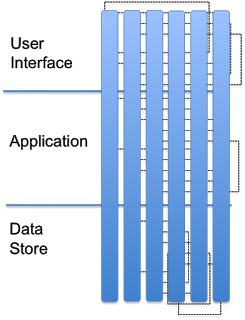
This is simply not economical for the medium to long term. With this approach, the enterprise ends up with 10-100's of full proprietary stacks (the blue bars), and no opportunity to innovate/customize. And worst of all: the enterprise has no leverage in their investments. Every time they need a capability, they have to re-buy capabilities they already have. Like A-Rod in 2002, they will start to regret their short term gratification decisions. To repeat, I understand that some companies have been successful in the short term with the instant gratification model. I just don't think its the right model for enterprises.
This brings us to the application server analogy. Given the data growth (size and variety) that we have seen in the last 3 years and will see in the next 10 years, an enterprise must have a flexible platform for managing that data. Such a platform will leverage all information sources, will annotate/organize that data, will provide real-time analysis, will allow the enterprise to write their own applications or buy 3rd party applications, etc. It will become the "Information Bus" for the enterprise. Todd used the phrase Next Generation Middleware during our exchange on this topic at the Strata Conference panel (see the 22 min mark). Whether its the "information bus" or next generation middleware, the graphic below illustrates the leverage that this approach will give an enterprise.

Intelligent enterprises do not make short term gratification decisions en masse. They might make them to solve point problems from time to time. But, it won't be their strategy. For that reason, I believe we will see Big Data emerge as a true platform...the Information Bus of the future.
A simple example from baseball:
As it became obvious that steroids enhanced performance, many players turned to the 'juice', to drive their short term performance. However, they quickly learned that it was not sustainable. Once you stop or overuse it, your performance and stability begins to breakdown. At the risk of picking on A-Rod, its fairly obvious when you look at a simple graph below. Note: the yellow star is when he admitted to starting to use steroids..
So, good for short term...disaster in the long term.
Turning to Big Data...
I believe an enterprise has to approach this problem with the long term in mind. There are a number of approaches for short term gratification, but they will not scale to support an enterprise economically in the long term. This is why I have alluded to the application server analogy for Big Data a few times (most recently here and here). Let me use some basic graphics to illustrate this analogy.
Typical/Simplistic View of an Enterpise
Simply put, an enterprise IT organization invests across all 3 layers and on integration inbetween.
However, as I look at emerging Big Data solutions, I'm seeing a pattern that looks like this:
The blue bar represents a 3rd party product that provides the entire stack, in proprietary packaging. This approach drives instant gratification. There is a single purchase, the enterprise gets the entire stack, etc. There are new companies that have been successful with this model. But that being said, I am not convinced this is a great approach for an enterprise longer term. Here is why.
Unfortunately, enterprises are not as simple as I depicted above. They often look more like this:
Enterprises are complex, they evolve, they buy, they build, they customize, etc. If you try to take the 'proprietary stack' approach to solving your problems, your enterprise will eventually look like this:
This is simply not economical for the medium to long term. With this approach, the enterprise ends up with 10-100's of full proprietary stacks (the blue bars), and no opportunity to innovate/customize. And worst of all: the enterprise has no leverage in their investments. Every time they need a capability, they have to re-buy capabilities they already have. Like A-Rod in 2002, they will start to regret their short term gratification decisions. To repeat, I understand that some companies have been successful in the short term with the instant gratification model. I just don't think its the right model for enterprises.
This brings us to the application server analogy. Given the data growth (size and variety) that we have seen in the last 3 years and will see in the next 10 years, an enterprise must have a flexible platform for managing that data. Such a platform will leverage all information sources, will annotate/organize that data, will provide real-time analysis, will allow the enterprise to write their own applications or buy 3rd party applications, etc. It will become the "Information Bus" for the enterprise. Todd used the phrase Next Generation Middleware during our exchange on this topic at the Strata Conference panel (see the 22 min mark). Whether its the "information bus" or next generation middleware, the graphic below illustrates the leverage that this approach will give an enterprise.
Intelligent enterprises do not make short term gratification decisions en masse. They might make them to solve point problems from time to time. But, it won't be their strategy. For that reason, I believe we will see Big Data emerge as a true platform...the Information Bus of the future.
IBM Big Data : A More Detailed Look
While we have had our Big Data Symposium this year and numerous analyst meetings, I think an update on our progress in Big Data is always helpful. Some of this may be well known already, but I want to give a comprehensive view. I've also included a slideshare below, which provides more detail. I would break down our Big Data strategy and focus into 6 areas:
1) Commitment to Open Source
I blogged about it here too, but I will restate: we are committed to Apache for our Big Data products and efforts. We have a long history in contributing to open source (see the slideshare below) and we have Hadoop committers and Lucene committers, to name a few. Given our commitment to Apache, we do not have a desire to be in the Hadoop distribution business.
2) Big Data as a Platform
We believe that clients will look to Big Data as a platform for managing all of their information assets. This is why I continue to allude to the application server as the best analogy for Big Data, instead of datawarehousing or databases. With Big Data as a platform, clients can write their own applications, buy 3rd party applications, or work with IBM for applications; either way, those applications will leverage the Big Data platform as the source of all data types, at scale. This will be very economical for large enterprises, as they leverage the platform across their business. Enterprises that become myopically focused on building out unique infrastructure for every use case, will find that to be very expensive and un-sustainable over time.
3) Data-in-Motion and Data-at-rest
If an enterprise cannot address both classes of problems, their Big Data strategy will not scale to meet their needs. For this reason, we continue to focus on delivering a Big Data platform that addresses both items: real-time/streaming analysis, as well as annotating/managing various data types at scale. A Big Data strategy that only addresses one of these is not a strategy: its a short term Band-Aid.
4) Research-led Capabilities
A Big Data platform is only as valuable as the capabilities that define its utility. Luckily, IBM Research has been focused on this problem for over a decade. Accordingly, we can deliver enterprise capabilites around Big Data that do not exist anywhere else:
-Text Analytics (System T)
-Machine Learning (System ML)
-Visualization
-Hardened and tested File System (POSIX compliant)
-Workload Management
-Security
-Optimization (Adaptive MapReduce)
-Large Scale Indexing
5) Integration
Big Data cannot be a silo. For enterprises, it must plug into all of their existing infrastructure investments. Therefore, we made integration a fore-thought, not an afterthought. We are delivering integration with IBM and non-IBM enterprise software products.
6) Success
The first 5 points don't mean much, if you can't demonstrate success. Fortunately, we can. We will release our first Big Data reference book at IOD in October. In it, you will see clients that are seeing real business impact from our Big Data products. You will also see what IBM has done for our own business with our Big Data capabilities. That being said, our real secret to creating success is partnership: working side-by-side with clients to prove out their business cases.
1) Commitment to Open Source
I blogged about it here too, but I will restate: we are committed to Apache for our Big Data products and efforts. We have a long history in contributing to open source (see the slideshare below) and we have Hadoop committers and Lucene committers, to name a few. Given our commitment to Apache, we do not have a desire to be in the Hadoop distribution business.
2) Big Data as a Platform
We believe that clients will look to Big Data as a platform for managing all of their information assets. This is why I continue to allude to the application server as the best analogy for Big Data, instead of datawarehousing or databases. With Big Data as a platform, clients can write their own applications, buy 3rd party applications, or work with IBM for applications; either way, those applications will leverage the Big Data platform as the source of all data types, at scale. This will be very economical for large enterprises, as they leverage the platform across their business. Enterprises that become myopically focused on building out unique infrastructure for every use case, will find that to be very expensive and un-sustainable over time.
3) Data-in-Motion and Data-at-rest
If an enterprise cannot address both classes of problems, their Big Data strategy will not scale to meet their needs. For this reason, we continue to focus on delivering a Big Data platform that addresses both items: real-time/streaming analysis, as well as annotating/managing various data types at scale. A Big Data strategy that only addresses one of these is not a strategy: its a short term Band-Aid.
4) Research-led Capabilities
A Big Data platform is only as valuable as the capabilities that define its utility. Luckily, IBM Research has been focused on this problem for over a decade. Accordingly, we can deliver enterprise capabilites around Big Data that do not exist anywhere else:
-Text Analytics (System T)
-Machine Learning (System ML)
-Visualization
-Hardened and tested File System (POSIX compliant)
-Workload Management
-Security
-Optimization (Adaptive MapReduce)
-Large Scale Indexing
5) Integration
Big Data cannot be a silo. For enterprises, it must plug into all of their existing infrastructure investments. Therefore, we made integration a fore-thought, not an afterthought. We are delivering integration with IBM and non-IBM enterprise software products.
6) Success
The first 5 points don't mean much, if you can't demonstrate success. Fortunately, we can. We will release our first Big Data reference book at IOD in October. In it, you will see clients that are seeing real business impact from our Big Data products. You will also see what IBM has done for our own business with our Big Data capabilities. That being said, our real secret to creating success is partnership: working side-by-side with clients to prove out their business cases.
IBM and Big Data
View more presentations from robdthomas
Big Data at IOD
Here are all of the big data sessions at IOD:
In addition to this, we will release our big data reference book, host an exclusive dinner for our big data clients, and have a big data forum in the exhibition area!
Big Data at IOD
View more presentations from robdthomas.
In addition to this, we will release our big data reference book, host an exclusive dinner for our big data clients, and have a big data forum in the exhibition area!
Big Data at Strata Conference
I had the chance to join a great discussion on Big Data last week at Strata. Video below.
Based on the dialogue, I highlighted 3 points:
1) My view of the Big Data ecosystem that is forming
2) Why Hadoop-alone may mean failure for enterprises in 2012
3) Why the application server market is a better analogy than the database market, when it comes to Big Data
I will do longer blog posts on each of these topics soon.
Lastly, based on a few requests I received, here is the chart I used on the Big Data ecosystem:
Based on the dialogue, I highlighted 3 points:
1) My view of the Big Data ecosystem that is forming
2) Why Hadoop-alone may mean failure for enterprises in 2012
3) Why the application server market is a better analogy than the database market, when it comes to Big Data
I will do longer blog posts on each of these topics soon.
Lastly, based on a few requests I received, here is the chart I used on the Big Data ecosystem:
Big Data Ecosystem
View more presentations from robdthomas.